
Компания Just IT разработала комплексное решение с использованием искусственного интеллекта.
Крупное предприятие в сфере производства и продажи ликероводочных изделий обратилось к нам с задачей оптимизации процесса адаптации новых сотрудников. Компания ежегодно принимает на работу до 500 новых специалистов различных профилей, и процесс их знакомства с предприятием требовал значительных временных затрат со стороны HR-службы.
Ключевые проблемы, требовавшие решения:
Поставленные цели:
Особенности проекта:
Пилотная версия системы была рассчитана на ключевые производственные должности предприятия, включая операторов линий розлива, инженеров-технологов, специалистов по контролю качества и другие ключевые позиции производственного цикла, а также некоторые административные должности.
Выбор технологического стека
Для реализации проекта мы выбрали следующие технологии:
Платформа для чат-бота:
Бэкенд:
NLP-компоненты:
Инфраструктура:
Архитектура решения [LM(IL1][LM(IL2]
Решение построено на микросервисной архитектуре, состоящей из следующих компонентов:
Крупное предприятие в сфере производства и продажи ликероводочных изделий обратилось к нам с задачей оптимизации процесса адаптации новых сотрудников. Компания ежегодно принимает на работу до 500 новых специалистов различных профилей, и процесс их знакомства с предприятием требовал значительных временных затрат со стороны HR-службы.
Ключевые проблемы, требовавшие решения:
- Высокая нагрузка на HR-специалистов — каждый новый сотрудник требовал индивидуального внимания и сопровождения.
- Разрозненность информации — данные о компании, правилах, процедурах хранились в разных источниках.
- Несистематизированный процесс адаптации — отсутствовал единый стандарт информирования сотрудников.
- Низкая скорость получения ответов — для решения даже базовых вопросов новичкам приходилось обращаться к коллегам или HR.
Поставленные цели:
- Автоматизировать процесс первичной адаптации сотрудников
- Обеспечить круглосуточный доступ к базовой информации о компании
- Снизить нагрузку на HR-отдел
- Стандартизировать информацию, предоставляемую новым сотрудникам
- Сократить время адаптации персонала
Особенности проекта:
Пилотная версия системы была рассчитана на ключевые производственные должности предприятия, включая операторов линий розлива, инженеров-технологов, специалистов по контролю качества и другие ключевые позиции производственного цикла, а также некоторые административные должности.
Выбор технологического стека
Для реализации проекта мы выбрали следующие технологии:
Платформа для чат-бота:
- Telegram Bot API — для создания интерфейса бота в Telegram
- Python — в качестве основного языка программирования
- Aiogram 3.0 — асинхронный фреймворк для создания Telegram-ботов
Бэкенд:
- Django — для разработки панели администратора и API
- PostgreSQL — для хранения структурированных данных
- Redis — для кэширования и управления состояниями
NLP-компоненты:
- BERT (Sentence-BERT) — для векторизации запросов пользователей
- FAISS — для эффективного поиска по векторам
- Natasha — для обработки русскоязычных текстов
- SpaCy — для общего NLP-пайплайна
Инфраструктура:
- Docker — для контейнеризации компонентов
- Kubernetes — для оркестрации контейнеров
- GitHub Actions — для CI/CD
- Prometheus + Grafana — для мониторинга
Архитектура решения [LM(IL1][LM(IL2]
Решение построено на микросервисной архитектуре, состоящей из следующих компонентов:
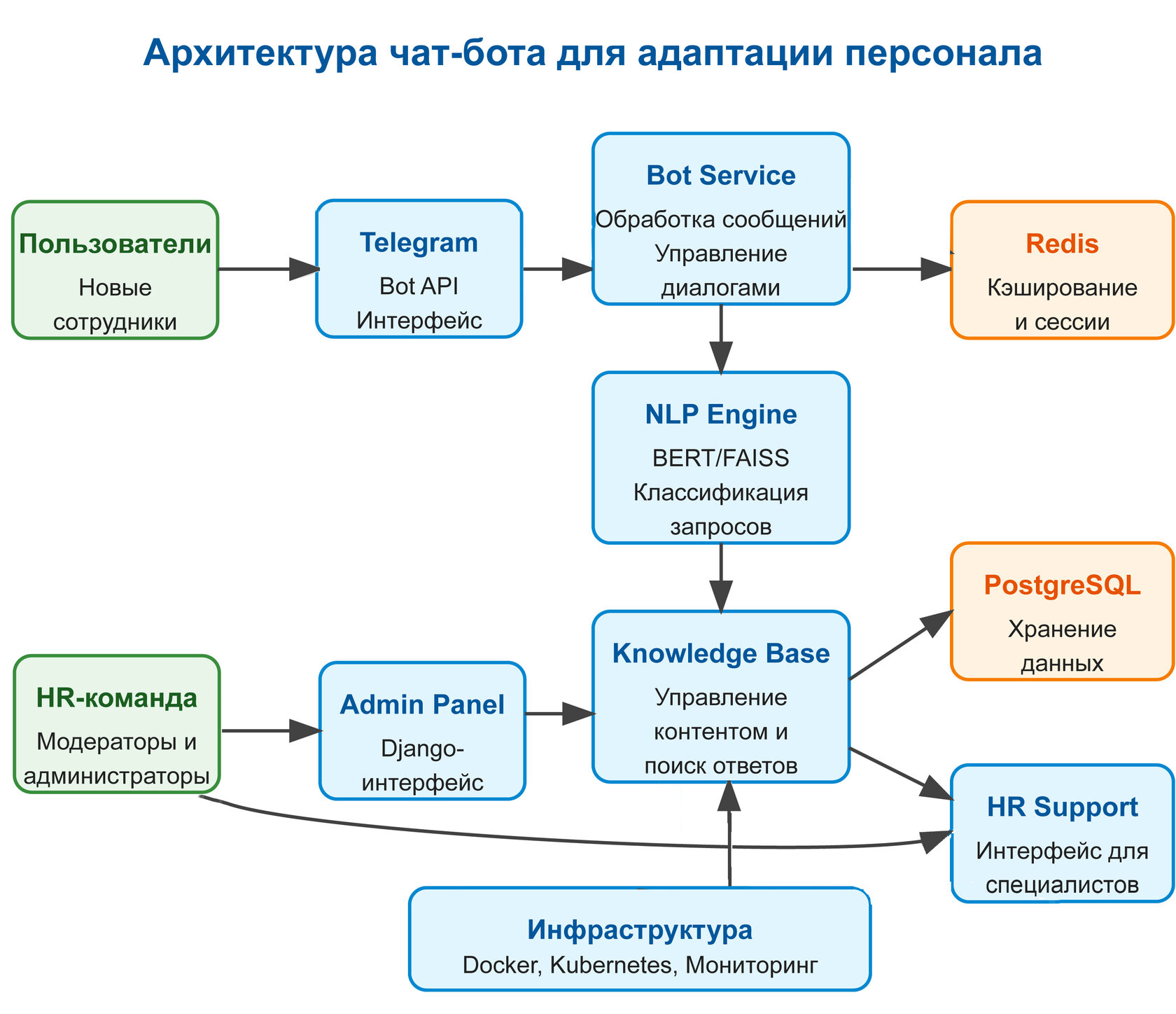
1. Telegram Bot Service
Сервис, напрямую взаимодействующий с Telegram Bot API. Отвечает за:
- Прием сообщений от пользователей
- Отправку ответов
- Реализацию интерфейса взаимодействия (кнопки, меню)
- Управление сессиями пользователей
2. NLP Engine
Компонент для обработки естественного языка:
- Понимание запросов пользователей
- Классификация вопросов по тематикам
- Извлечение ключевых сущностей из запросов
- Векторизация вопросов для эффективного поиска ответов
3. Knowledge Base Management
Подсистема управления базой знаний:
- Хранение информации о компании, правилах, процедурах
- Поиск релевантных ответов на запросы
- Индексирование контента
- API для обновления базы знаний
4. Admin Panel
Веб-интерфейс для администраторов системы:
- Управление контентом базы знаний
- Анализ статистики использования
- Мониторинг неразрешенных запросов
- Настройка правил маршрутизации вопросов
5. Human Support Interface
Интерфейс для взаимодействия с HR-специалистами:
- Прием запросов, которые не может обработать бот
- Уведомления о необходимости вмешательства человека
- История взаимодействия с пользователем
Процесс реализации
Этап 1: Анализ и проектирование
Мы начали с глубокого анализа потребностей заказчика и разработки детальной концепции будущего решения. Провели серию интервью с HR-специалистами и представителями целевых должностей для определения наиболее частых вопросов новых сотрудников.
Для структуризации знаний была создана онтология, охватывающая:
- Информацию о компании (история, миссия, структура)
- Правила безопасности на производстве
- Организационные вопросы (оформление больничных, отпусков)
- Должностные инструкции и обязанности
- Техническую информацию для разных специальностей
Этап 2: Разработка базовой версии
На данном этапе мы создали:
- Базовую архитектуру системы
- Интеграцию с Telegram
- Простую базу знаний с ответами на часто задаваемые вопросы
- Административную панель для управления контентом
- Механизм перенаправления запросов на HR-специалистов
Ключевой особенностью стала реализация "интеллектуального" определения тематики вопроса. Мы использовали предобученную модель BERT, дообученную на специфическом корпусе текстов, относящихся к производству алкогольной продукции и процессам адаптации персонала.
Этап 3: Внедрение NLP-функциональности
Для повышения "интеллектуальности" бота, мы внедрили:
- Векторизацию запросов и поиск ближайших ответов в базе знаний
- Определение намерения пользователя (intent recognition)
- Извлечение ключевых сущностей из запросов
- Логику поддержания контекста диалога
Для работы с русскоязычными текстами активно использовалась библиотека Natasha, что позволило эффективно обрабатывать морфологические особенности русского языка.
Этап 4: Тестирование и оптимизация
Перед запуском пилотной версии мы провели:
- Функциональное тестирование всех компонентов
- Нагрузочное тестирование (симуляция одновременной работы до 100 пользователей)
- UX-тестирование с фокус-группой из реальных сотрудников
- Тестирование точности ответов на различные типы запросов
По результатам тестирования были внесены корректировки в:
- Алгоритмы классификации запросов
- Пороговые значения схожести для выбора ответов
- Интерфейс взаимодействия с пользователем
Этап 5: Пилотный запуск
Пилотный запуск состоялся с группой из 30 новых сотрудников разных специальностей. В течение месяца мы собирали обратную связь и вносили корректировки в систему.
Основные метрики, которые отслеживались в ходе пилота:
- Процент успешно обработанных запросов (без участия человека)
- Среднее время получения ответа
- Частота использования бота разными категориями сотрудников
- Количество переадресаций на HR-специалистов
- Удовлетворенность пользователей (на основе обратной связи)
Технические особенности реализации [LM(IL3]
Персонализация контента
Система автоматически определяет профиль пользователя и адаптирует информацию под его должность. Для этого при первой авторизации сотрудник указывает свою должность, после чего:
async def personalize_response(user_id, query, user_position):
# Получаем базовый ответ на запрос
base_response = await get_basic_response(query)
# Проверяем, нужна ли персонализация для этого типа запроса
if requires_personalization(query):
# Дополняем ответ информацией, специфичной для должности
position_specific_info = await get_position_specific_info(
query_type=classify_query(query),
position=user_position
)
# Комбинируем общую информацию со специфичной
return combine_responses(base_response, position_specific_info)
return base_response
Высокоскоростной поиск по базе знаний
Для обеспечения быстрых ответов на запросы реализован векторный поиск с использованием FAISS:
Для обеспечения быстрых ответов на запросы реализован векторный поиск с использованием FAISS:
class VectorSearch:
def __init__(self):
# Загружаем предобученную модель для русского языка
self.model = SentenceTransformer('DeepPavlov/rubert-base-cased-sentence')
# Инициализируем индекс FAISS
self.index = faiss.IndexFlatL2(768) # 768 - размерность BERT-эмбеддингов
# Загружаем и индексируем базу знаний
self.load_knowledge_base()
def load_knowledge_base(self):
# Получаем все Q&A пары из базы данных
qa_pairs = KnowledgeBase.objects.all().values('question', 'answer', 'id')
# Создаем текстовые представления вопросов
self.questions = [item['question'] for item in qa_pairs]
self.answers = [item['answer'] for item in qa_pairs]
self.ids = [item['id'] for item in qa_pairs]
# Получаем векторные представления вопросов
embeddings = self.model.encode(self.questions)
# Добавляем векторы в индекс
self.index.add(np.array(embeddings))
def search(self, query, top_k=5):
# Получаем векторное представление запроса
query_vector = self.model.encode([query])[0].reshape(1, -1)
# Ищем ближайших соседей
distances, indices = self.index.search(query_vector, top_k)
# Возвращаем результаты
results = []
for i, idx in enumerate(indices[0]):
if idx != -1: # Валидный индекс
results.append({
'question': self.questions[idx],
'answer': self.answers[idx],
'id': self.ids[idx],
'score': 1.0 - (distances[0][i] / 100.0) # Нормализуем оценку
})
return results
Система маршрутизации запросов
Одна из ключевых особенностей системы — интеллектуальная маршрутизация запросов:
Одна из ключевых особенностей системы — интеллектуальная маршрутизация запросов:
async def route_query(user_id, query):
# Классифицируем запрос
query_type = classify_query(query)
confidence = get_classification_confidence(query)
# Если уверенность в классификации высокая и есть ответ в базе знаний
if confidence > CONFIDENCE_THRESHOLD and has_knowledge_base_answer(query_type, query):
# Отвечаем из базы знаний
return await get_knowledge_base_response(query_type, query)
# Если уверенность низкая или ответа нет в базе знаний
else:
# Предлагаем перенаправить запрос HR-специалисту
await bot.send_message(
user_id,
"Я не уверен, что правильно понял вопрос. Хотите, чтобы я передал его HR-специалисту?",
reply_markup=create_transfer_keyboard()
)
# Сохраняем контекст для последующей обработки
await save_unresolved_query_context(user_id, query)
# Возвращаем None, так как ответ будет предоставлен позже
return None
Результаты внедрения
После успешного завершения пилотного проекта и перехода в промышленную эксплуатацию, были достигнуты следующие результаты:
Количественные показатели:
Качественные результаты:
Перспективы развития
На основе успешного опыта внедрения чат-бота для адаптации персонала, планируются следующие направления развития проекта:
Расширение функциональности HR-процессов:
Технологические улучшения:
Масштабирование решения:
Заключение
Проект по разработке чат-бота для адаптации персонала предприятия ликеро-водочной промышленности наглядно демонстрирует, как современные технологии искусственного интеллекта и обработки естественного языка могут эффективно решать практические задачи бизнеса.
Внедрение системы позволило значительно снизить нагрузку на HR-службу, стандартизировать процесс адаптации новых сотрудников и сократить время их интеграции в рабочие процессы. Комбинация технологических решений с глубоким пониманием бизнес-процессов заказчика обеспечила высокую практическую ценность реализованного проекта.
После успешного завершения пилотного проекта и перехода в промышленную эксплуатацию, были достигнуты следующие результаты:
Количественные показатели:
- 73% снижение количества базовых вопросов к HR-службе
- Сокращение времени адаптации новых сотрудников на 47%
- 89% точность ответов на запросы пользователей
- Более 15,000 обработанных запросов за первые три месяца эксплуатации
- 67% сотрудников активно используют бота в течение первого месяца работы
Качественные результаты:
- Стандартизация информации, предоставляемой новым сотрудникам
- Освобождение HR-специалистов для решения более сложных задач
- Повышение доступности информации для сотрудников 24/7
- Ускорение интеграции новых сотрудников в рабочие процессы
- Возможность аналитики частых запросов для дальнейшей оптимизации процессов
Перспективы развития
На основе успешного опыта внедрения чат-бота для адаптации персонала, планируются следующие направления развития проекта:
Расширение функциональности HR-процессов:
- Автоматизация подбора персонала с анализом резюме и их ранжированием
- Создание и управление базой потенциальных сотрудников
- Автоматическое оповещение кандидатов о релевантных вакансиях
- Первичный скрининг кандидатов с помощью чат-бота
- Сбор и анализ обратной связи от соискателей
Технологические улучшения:
- Внедрение алгоритмов машинного обучения для предиктивного анализа потребностей в персонале
- Интеграция с job-порталами и профессиональными соцсетями
- Улучшение распознавания квалификаций в резюме с помощью NLP
Масштабирование решения:
- Расширение функционала на все этапы жизненного цикла сотрудника в компании
- Создание единой HR-экосистемы с чат-ботом в качестве интерфейса
- Разработка мобильного приложения для кандидатов и сотрудников
Заключение
Проект по разработке чат-бота для адаптации персонала предприятия ликеро-водочной промышленности наглядно демонстрирует, как современные технологии искусственного интеллекта и обработки естественного языка могут эффективно решать практические задачи бизнеса.
Внедрение системы позволило значительно снизить нагрузку на HR-службу, стандартизировать процесс адаптации новых сотрудников и сократить время их интеграции в рабочие процессы. Комбинация технологических решений с глубоким пониманием бизнес-процессов заказчика обеспечила высокую практическую ценность реализованного проекта.